1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import math
import heapq
def weight_inverse(w):
return 1 / w
def weight_one(w):
return 1;
def weight_gaussian(dist, a=1, b=0, c=0.3):
return a * math.e ** (-(dist - b) ** 2 / (2 * c ** 2))
def knn(x, dataset, labels, k, norm=2, weight_fn=weight_gaussian):
n = dataset.shape[0]
d = []
for i in range(n):
heapq.heappush(d, (np.linalg.norm([x - dataset[i]], norm), i))
topk = np.array([np.asarray(heapq.heappop(d)) for i in range(k)])
summation = {}
for item in topk:
cls = y[int(item[1])]
if not cls in summation:
summation[cls] = 0
summation[cls] += weight_fn(item[0])
cls = None
score = 0
for item in summation:
if summation[item] > score:
cls = item
score = summation[item]
return cls
x = np.random.rand(2)
cls_wo = knn(x, sample, y, k, weight_fn=weight_one)
cls_wo = int(cls_wo)
cls_wi = knn(x, sample, y, k, weight_fn=weight_inverse)
cls_wi = int(cls_wi)
cls_wg = knn(x, sample, y, k, weight_fn=weight_gaussian)
cls_wg = int(cls_wg)
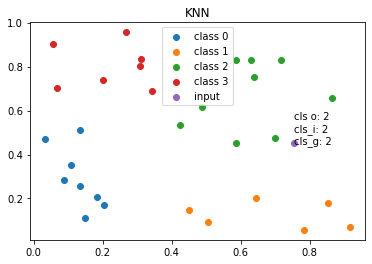
plt.title('KNN')
for i in range(k):
mask = y[:] == i
classified = sample[mask,:]
plt.scatter(classified[:,0], classified[:,1], label=f'class {i}')
plt.scatter(x[0], x[1], label=f'input')
plt.annotate(f'cls o: {cls_wo}\ncls_i: {cls_wi}\ncls_g: {cls_wg}', (x[0], x[1]))
plt.legend()
plt.show()
|