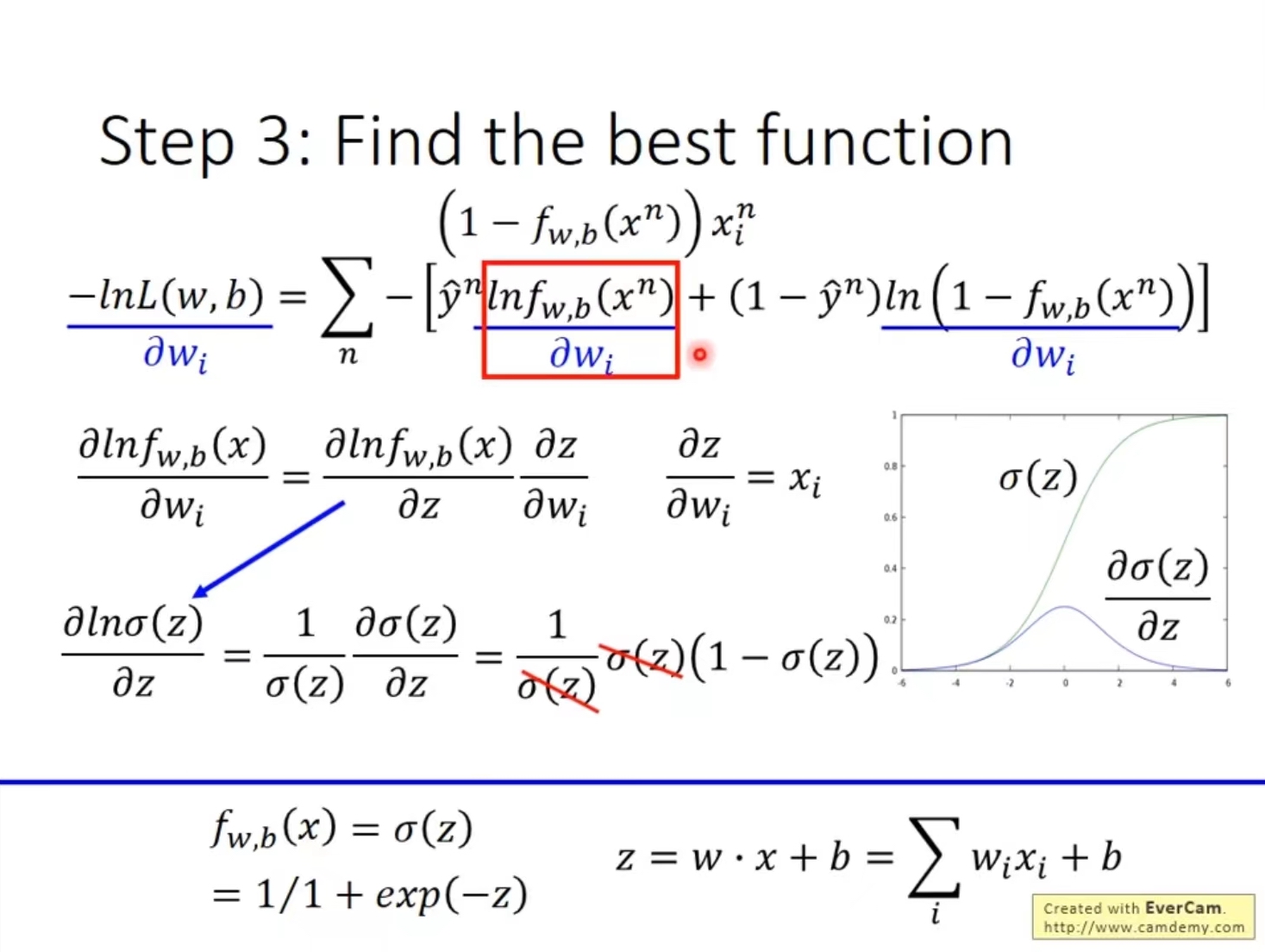
Sigmoid函数:σ ( z ) = ( 1 + e − z ) − 1 \sigma(z) = (1 + e^{-z})^{-1} σ ( z ) = ( 1 + e − z ) − 1
线性回归:z = w 0 x 0 + w 1 x 1 + . . . + w i x i = ∑ i w i x i z = w_0x_0 + w1_x1 + ... + w_ix_i = \sum_{i} w_ix_i z = w 0 x 0 + w 1 x 1 + . . . + w i x i = ∑ i w i x i z = W T X z = W^TX z = W T X
逻辑回归:σ ( z ) = σ ( w 0 x 0 + w 1 x 1 + . . . + w i x i ) = ( 1 + e − ( w 0 x 0 + w 1 x 1 + . . . + w i x i ) ) − 1 = ( 1 + e − W T X ) − 1 \sigma(z) = \sigma(w_0x_0 + w1_x1 + ... + w_ix_i) = (1 + e^{-(w_0x_0 + w1_x1 + ... + w_ix_i)})^{-1} = (1 + e^{-W^TX})^{-1} σ ( z ) = σ ( w 0 x 0 + w 1 x 1 + . . . + w i x i ) = ( 1 + e − ( w 0 x 0 + w 1 x 1 + . . . + w i x i ) ) − 1 = ( 1 + e − W T X ) − 1
逻辑回归的损失函数推导用到的知识点就是微分偏导,链式法则,还有一些对数运算法则。
详细过程就不写在这了,写公式十分容易错漏符号,容易误导人。
我试着推导了一下,还是觉得有点困难。搜了一圈,觉得讲得最好的还是台大李宏毅的课程。截了三张图放这里。
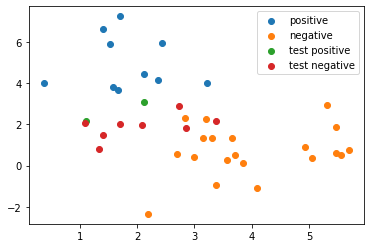
下面的code生成了正负样本训练数据,一份测试数据,使用了sklearn的LR进行训练和预测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import numpy as npimport matplotlib.pyplot as pltfrom sklearn import linear_modeldef gen_2dsample_data (n, ex, ey, sigmax, sigmay, label ): x = np.ndarray([n, 2 ], np.float32) y = np.ones(n) * label for i in range (n): x[i] = np.array([ex + np.random.randn() * sigmax, ey + np.random.randn() * sigmay]) return x, y s1x, s1y = gen_2dsample_data(10 , 1 , 5 , 1 , 1 , 1 ) s2x, s2y = gen_2dsample_data(20 , 4 , 1 , 1 , 1 , 0 ) test_x, _ = gen_2dsample_data(10 , 2 , 2 , 1 , 1 , 0 ) x = np.concatenate((s1x, s2x)) y = np.concatenate((s1y, s2y)) model = linear_model.LogisticRegression() model.fit(x, y) p1y = model.predict(s1x) p2y = model.predict(s2x) test_y = model.predict(test_x) print (f'ground truth: {y} ' )print (f'positive training dataset predict result: {model.predict(s1x)} ' )print (f'negative training dataset predict result: {model.predict(s2x)} ' )print (f'test dataset predict result: {test_y} ' )plt.scatter(s1x[:,0 ], s1x[:,1 ], label='positive' ) plt.scatter(s2x[:,0 ], s2x[:,1 ], label='negative' ) test_true_mask = test_y[:] == 1 test_false_mask = test_y[:] == 0 test_positive = test_x[test_true_mask, :] test_negative = test_x[test_false_mask, :] plt.scatter(test_positive[:,0 ], test_positive[:,1 ], label='test positive' ) plt.scatter(test_negative[:,0 ], test_negative[:,1 ], label='test negative' ) plt.legend() plt.show()
ground truth: [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.]
positive training dataset predict result: [1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
negative training dataset predict result: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
test dataset predict result: [1. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
可以看到经过分布在左上角的正样本(蓝色),和分布在右下角的负样本(橙色)分类后,对测试数据也进行了很好的分类。
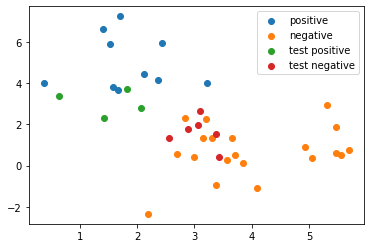
下面是我实现的代码,使用梯度下降优化loss。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 epsilon = 0.1 def fz (x, w ): z = 0 for i in range (len (x)): z += w[i] * x[i] return z def sigmoid (x, w ): return 1 / (1 + np.exp(-fz(x, w))) def logicstic_loss (x, y, w ): return 1 - (y * sigmoid(x, w) + (1 - y) * (1 - sigmoid(x, w))) def logicstic_optimizer (x, y, w, xi ): return (y - sigmoid(x, w)) * xi def fit_one_epoch (x, y, w, optimizer, epsilon ): batch_size = len (y) weights_size = len (w) gradient = np.zeros(weights_size) for j in range (weights_size): for i in range (batch_size): xb = np.append(x[i], [1.0 ]) gradient[j] += optimizer(xb, y[i], w, xb[j]) for j in range (weights_size): gradient[j] = gradient[j] / batch_size w[j] = w[j] + epsilon * gradient[j] return w def evaluate_loss (x, y, w ): loss = 0 batch_size = len (y) for i in range (batch_size): loss += logicstic_loss(x[i], y[i], w) return loss def logicstic_regression_train (x, y, epochs, epsilon, early_stop ): ncoeff = len (x[0 ]) w = np.zeros(ncoeff + 1 ) for i in range (epochs): w = fit_one_epoch(x, y, w, logicstic_optimizer, epsilon) loss = evaluate_loss(x, y, w) if i % 100 == 99 : print (f'epoch:{i+1 :8 } loss:{loss} w={w} ' ) if loss < early_stop: break return w w = logicstic_regression_train(x, y, 5000 , epsilon, 1 )
epoch: 100 loss:1.6624532849626095 w=[-1.22919783 1.22317253 -0.16759952]
epoch: 200 loss:1.1455727662566828 w=[-1.52690226 1.53598957 -0.22404162]
训练设置5000个epochs或loss低于1停止。最终得到的w,可以用于预测:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def logicstic_regression_predict (x, w ): y = np.zeros(len (x)) for i in range (len (x)): y[i] = 1 if sigmoid(x[i], w) >= 0.5 else 0 return y test_x2, _ = gen_2dsample_data(10 , 2 , 2 , 1 , 1 , 0 ) test_y2 = logicstic_regression_predict(test_x2, w) plt.scatter(s1x[:,0 ], s1x[:,1 ], label='positive' ) plt.scatter(s2x[:,0 ], s2x[:,1 ], label='negative' ) test_true_mask = test_y2[:] == 1 test_false_mask = test_y2[:] == 0 test_positive = test_x2[test_true_mask, :] test_negative = test_x2[test_false_mask, :] plt.scatter(test_positive[:,0 ], test_positive[:,1 ], label='test positive' ) plt.scatter(test_negative[:,0 ], test_negative[:,1 ], label='test negative' ) plt.legend() plt.show()