原本打算使用python代码实现梯度下降曲线拟合。搜索了一圈没有找到讲得非常详细的文章。自己实践了一下记录在此。
注:公式是后期整理的没有很仔细,也许会有些细节上的问题,仅供参考。
首先确定拟合曲线的函数是怎样的,这里用一元k次方程:
y ( w 0 , w 1 . . . w k ) = w 0 + w 1 x + w 2 x 2 . . . + w k x k = ∑ n = 0 k w n x n y(w_0,w_1...w_k) = w_0 + w_1 x + w_2 x^2 ... + w_k x^k = \sum_{n=0}^{k} {w_n}{x^n} y ( w 0 , w 1 . . . w k ) = w 0 + w 1 x + w 2 x 2 . . . + w k x k = ∑ n = 0 k w n x n
然后,确定使用最小二乘损失函数:
L = ∑ i = 0 j 1 2 j ( y i ^ − 𝑦 i ) 2 L = \sum_{i=0}^{j} \frac{1}{2j} (\hat{y_i} - 𝑦_i) ^ 2 L = ∑ i = 0 j 2 j 1 ( y i ^ − y i ) 2
这里的y ^ \hat{y} y ^ y i y_i y i j j j
梯度下降优化,就是对loss函数的每一个w权重分量分别计算梯度,然后每次迭代更新一次梯度。
对于每个w权重的梯度,也就是每个w g w_g w g d d w g L = d d w g ∑ i = 0 j 1 2 j ( y i ^ − 𝑦 i ) 2 \frac{d}{dw_g}L = \frac{d}{dw_g}\sum_{i=0}^{j} \frac{1}{2j} (\hat{y_i} - 𝑦_i) ^ 2 d w g d L = d w g d ∑ i = 0 j 2 j 1 ( y i ^ − y i ) 2
这里以k = 2 k = 2 k = 2
( w 0 2 + w 0 w 1 x + w 0 w 2 2 − w 0 y ( w_0^2 + w_0w_1x + w0w_2^2 - w_0y ( w 0 2 + w 0 w 1 x + w 0 w 2 2 − w 0 y
+ w 0 w 1 x + w 1 2 x 2 + w 1 w 2 x 3 − w 1 x y + w_0w_1x + w_1^2x^2 + w_1w_2x^3 - w_1xy + w 0 w 1 x + w 1 2 x 2 + w 1 w 2 x 3 − w 1 x y
+ w 0 w 2 x 2 + w 1 w 2 x 3 + w 2 2 x 4 − w 2 x 2 y + w_0w_2x^2 + w_1w_2x^3 + w_2^2x^4 - w_2x^2y + w 0 w 2 x 2 + w 1 w 2 x 3 + w 2 2 x 4 − w 2 x 2 y
− w 0 y − w 1 x y − w 2 x 2 y + y 2 ) - w_0y - w_1xy - w_2x^2y + y^2) − w 0 y − w 1 x y − w 2 x 2 y + y 2 )
对w 1 w_1 w 1
= ( w 0 x + w 0 x + 2 w 1 x 2 + w 2 x 3 − x y + w 2 x 3 − x y ) = (w_0x + w_0x + 2w_1x^2 + w_2x^3 - xy + w_2x^3 - xy) = ( w 0 x + w 0 x + 2 w 1 x 2 + w 2 x 3 − x y + w 2 x 3 − x y )
= ( 2 w 0 x + 2 w 1 x 2 + 2 w 2 x 3 − 2 x y ) = (2w_0x + 2w_1x^2 + 2w_2x^3 - 2xy) = ( 2 w 0 x + 2 w 1 x 2 + 2 w 2 x 3 − 2 x y )
= 2 x ( w 0 + w 1 x + w 2 x 2 − y ) = 2x(w_0 + w_1x + w_2x^2 - y) = 2 x ( w 0 + w 1 x + w 2 x 2 − y )
对w 2 w_2 w 2
= 2 x 2 ( w 0 + w 1 x + w 2 x 2 − y ) = 2x^2(w_0 + w_1x + w_2x^2 - y) = 2 x 2 ( w 0 + w 1 x + w 2 x 2 − y )
所以 d d w g L = x g ( ∑ n = 0 k w n x n − y ) \frac{d}{dw_g}L = x^g(\sum_{n=0}^{k} {w_n}{x^n} - y) d w g d L = x g ( ∑ n = 0 k w n x n − y )
对于每次迭代权重w k w_k w k
g r a d i e n t ( w g ) = ∑ i = 1 j 1 j x g ( ∑ n = 0 k w n x n − y ) gradient(w_g) = \sum_{i=1}^{j} \frac{1}{j} x^g(\sum_{n=0}^{k} {w_n}{x^n} - y) g r a d i e n t ( w g ) = ∑ i = 1 j j 1 x g ( ∑ n = 0 k w n x n − y )
下面就是权重更新的公式:
w k = w k − ϵ d L d w g w_k = w_k - \epsilon \frac{dL}{d w_g} w k = w k − ϵ d w g d L
其中 ϵ \epsilon ϵ
这里设要拟合一个接近一元三次函数f ( x ) = a x 3 + b x 2 + c x + d f(x) = ax^3+bx^2+cx+d f ( x ) = a x 3 + b x 2 + c x + d
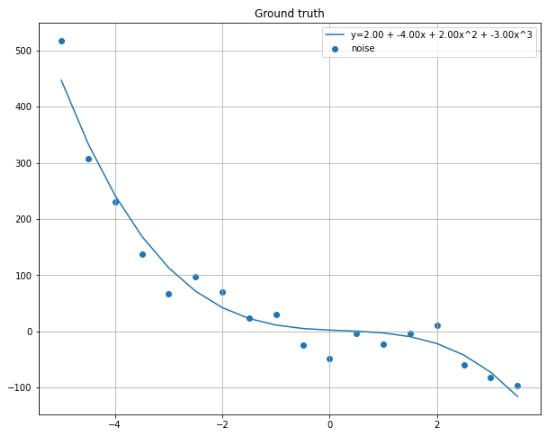
1 2 3 4 5 6 7 8 9 10 import mathimport numpy as npimport matplotlib.pyplot as pltground_truth_w = [-3 , 2 , -4 , 2 ] ground_truth_x = np.arange(-5 , 4 , 0.5 ) ground_truth_y = np.polyval(ground_truth_w, ground_truth_x) ground_truth_y_noise = [y + np.random.randn() * 30 for y in ground_truth_y]
以上散点是要拟合的曲线的输入样本。
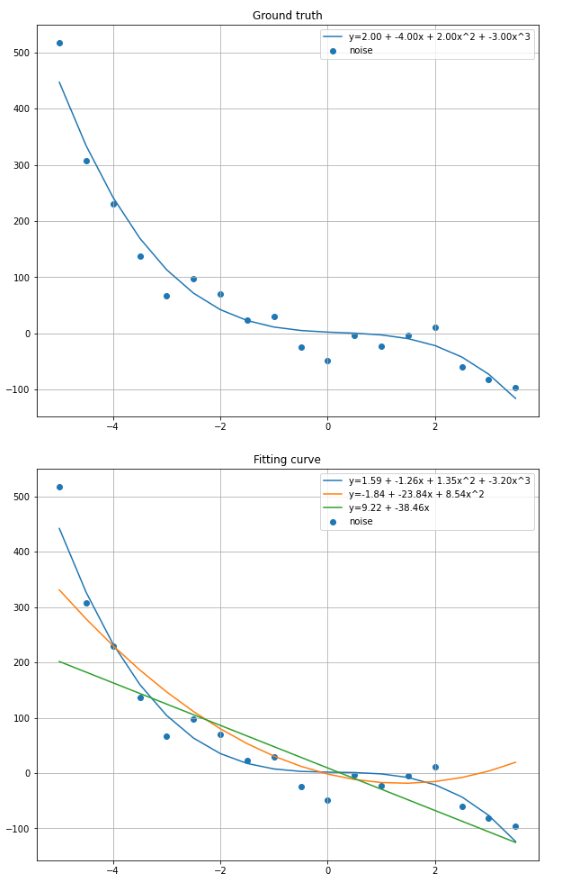
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import mathimport numpy as npimport matplotlib.pyplot as pltbatch_size = len (ground_truth_y) eps = [0.0001 , 0.0001 , 0.0001 ] weights = [np.zeros(4 ), np.zeros(3 ), np.zeros(2 )] epochs = [2000 , 2000 , 2000 ] def evaluate_loss (x, y, weights ): s = 0 bs = len (y) for i in range (bs): s = s + (np.polyval(weights, x[i]) - y[i]) ** 2 return s / bs; def evaluate_gradient (x, y, weights, epsilon ): power = len (weights) for g in range (len (weights)): gradient = 0 for i in range (batch_size): gradient += x[i] ** (power - 1 - g) * (np.polyval(weights, x[i]) - y[i]) / batch_size weights[g] = weights[g] - epsilon * gradient def fit_curve (x, y, weights, epochs, epsilon ): for i in range (epochs): evaluate_gradient(x, y, weights, epsilon) if i % 100 == 0 : loss = evaluate_loss(x, y, weights) print (f'epoch:{i:8 } loss:{loss:.4 f} ' ) for i in range (len (weights)): fit_curve(ground_truth_x, ground_truth_y_noise, weights[i], epochs[i], eps[i])
输出图像:
学习率太大, 样本数据y值太大
loss下降很小说明优化空间已经不大了
可能之一是gradient算错了,比如x[i]的指数算错,或者weights的顺序没对应上之类。