
记第一次LoRA训练
记第一次LoRA训练
这两天断断续续的在了解一些关于LLM fine-tuning和LoRA训练的知识,但是一直还没上手实践,感觉眼睛学会了个7、8成。
就在刚才到处逛看到一个叫伶荔的project,一看owner好家伙是深圳大学计算机视觉研究所,母校。
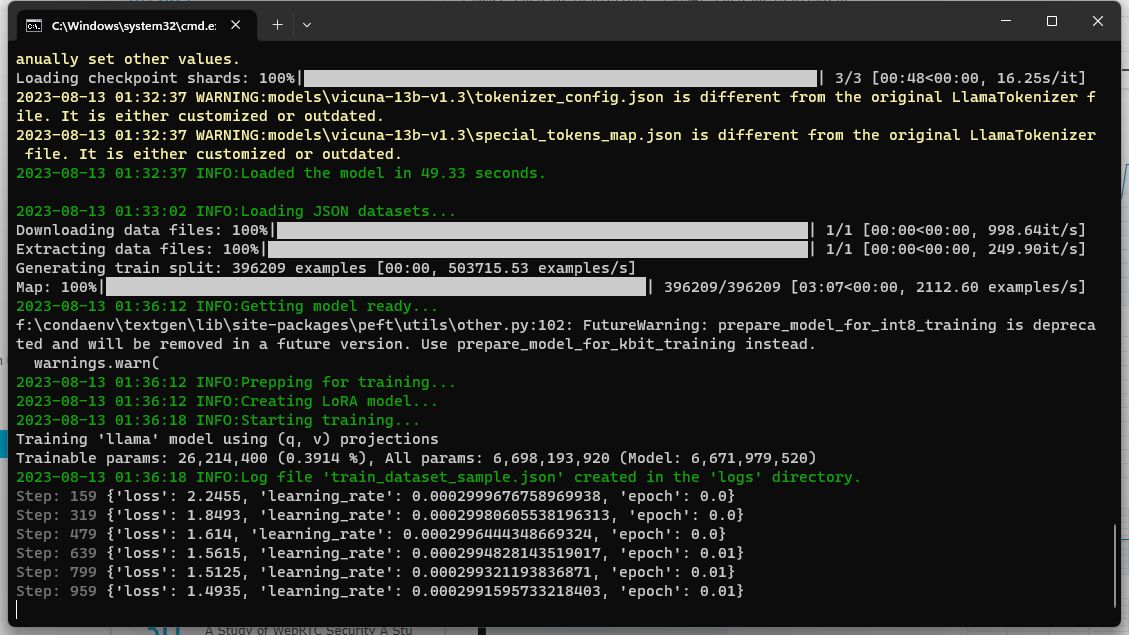
洗澡前打算交点活给GPU干,于是想让它训练一个LoRA。数据集就用Linly提到的instructions,我只取了其中的CSL部分。
原本打算基于Llama-2 13B GQPT模型训练,但是它报错,训练GPTQ模型的LoRA需要一个叫monkeypatch的包。这个包装不上
1 | except ImportError, e: |
好像是太老了,新python已经不支持except这种写法。急着洗澡没去仔细研究,于是换了个vicuna-13b-v1.3-hf,可以跑起来,就走开了。
洗澡真是个彻底放松的时间,sparks of inspiration come out。
之前还没有去了解的问题,突然就想通了,虽然不一定对,但是稍后准备再去调查一下,主要是两件事
- 如何扩词表?比如对英语模型加入中文的支持。
- 训练LLM时,lost function是什么?
我想到的答案:
扩词表也就是将token的数目增加,原本只有英语token,加入中文token。做法是直接在原token表后面新增新的token,分配新的token id。
而Lost function,则还是交叉熵。因为预测token实质上就是对输入作一个词表大小那么多个分类计算每一个token输出的概率。
接下来我会找资料继续学习验证我的猜想。
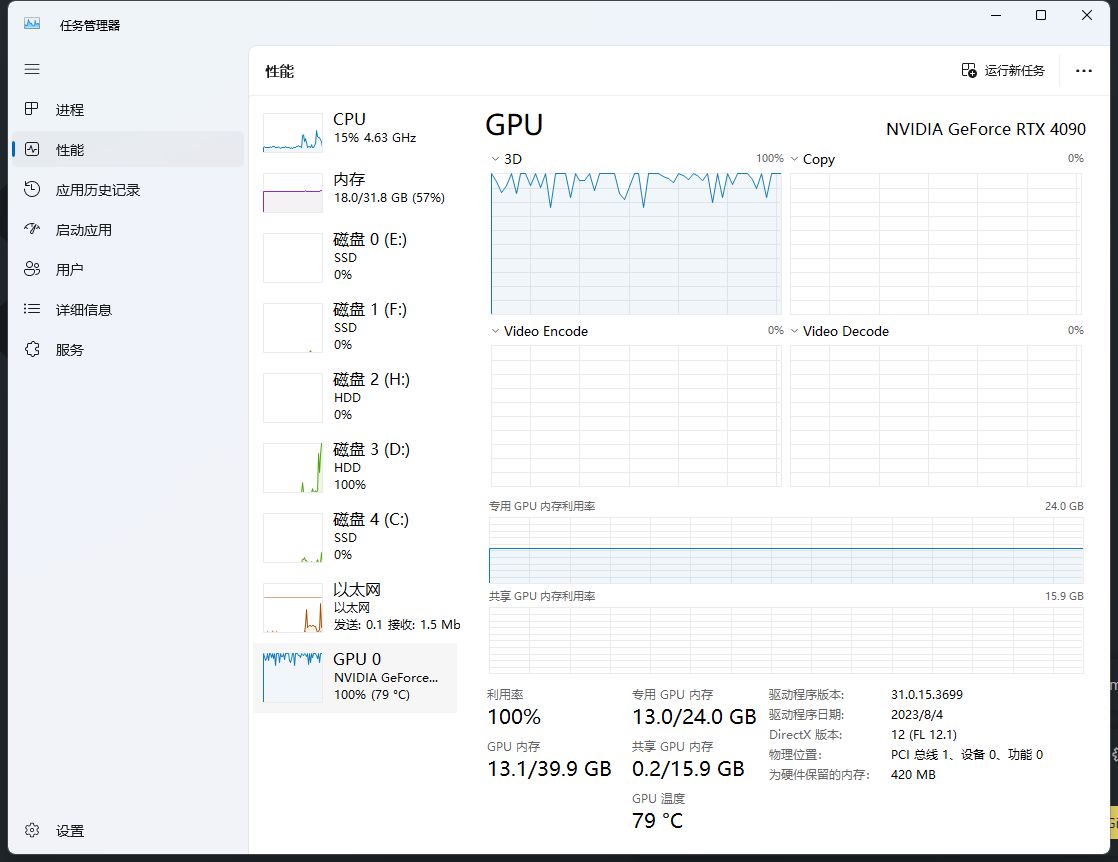
然后我要停止LoRA训练了。因为它发热真的很大,现在是夏天。
而且我不想我刚买两个月的4090这么早锻炼出8块腹肌。以后有空再去看看能不能白嫖Colab,实在不行就买国产GPU云算。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Stargazer!
